Multimodal Embedding Generator
Nov 16, 2025
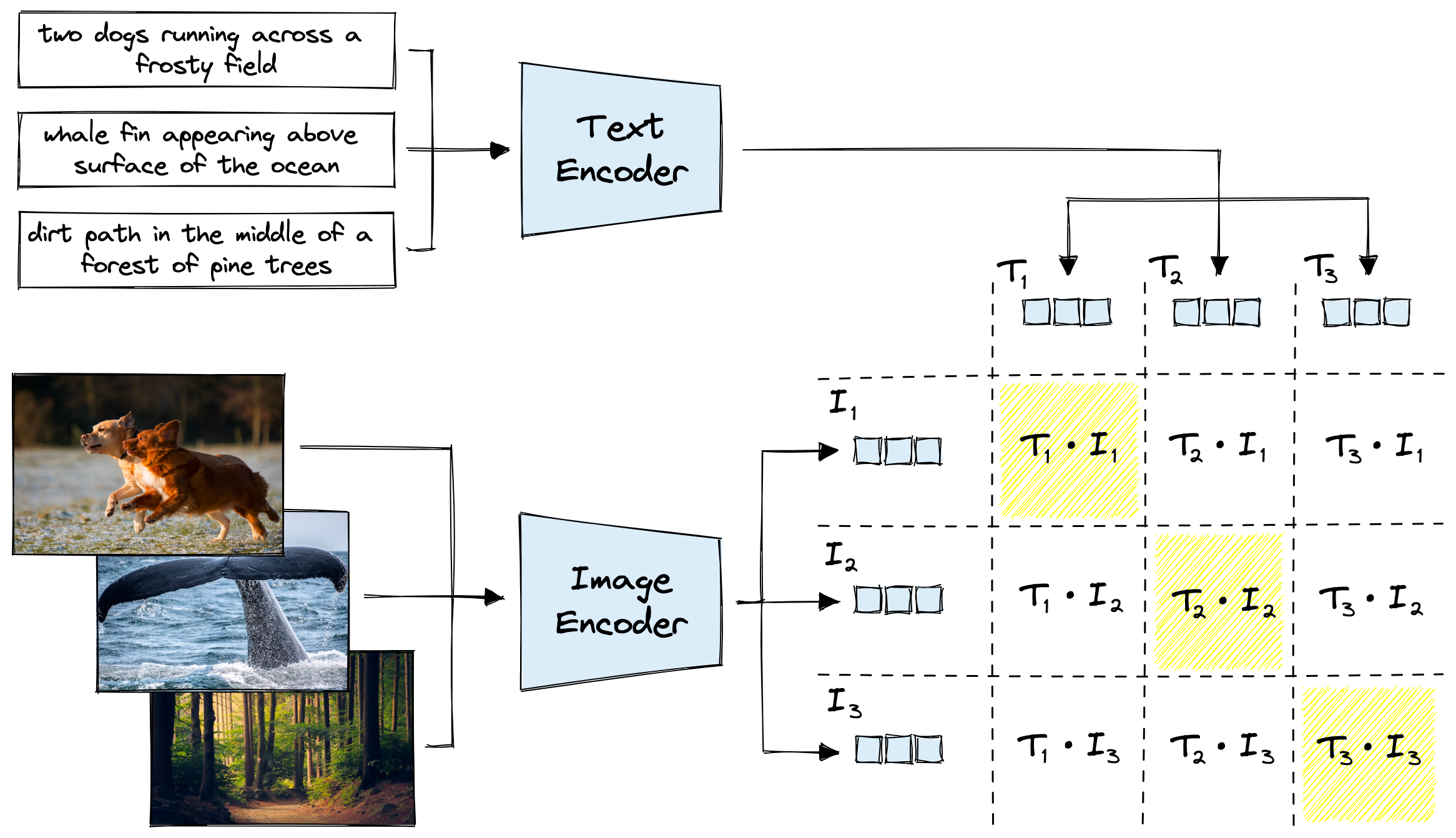
This project investigates how a neural network can connect images and language by converting them into a shared representation. The goal is to build a system that understands how visual and textual descriptions relate at a structural level. This is the core of many modern AI systems, from semantic search to visual question answering.
Dataset
The dataset consists of paired images and captions. Each caption describes the content of a specific image. This pairing allows the model to learn how visual features align with language.
multi_modal_dataset/ ├─ images/ │ ├─ image_001.png │ ├─ image_002.png │ └─ ... └─ captions.json
Example captions file entry:
{
"image_001.png": "A bird perched on a branch",
"image_002.png": "A futuristic city skyline at night"
}Embedding Generation
The system uses CLIP with the ViT-B32 backbone to generate embeddings. Each image and caption is converted into a vector that captures its meaning. These vectors are then normalized to ensure consistent comparison.
Image embedding:
Text embedding:
Similarity between embeddings is computed using cosine similarity:
Vector Storage
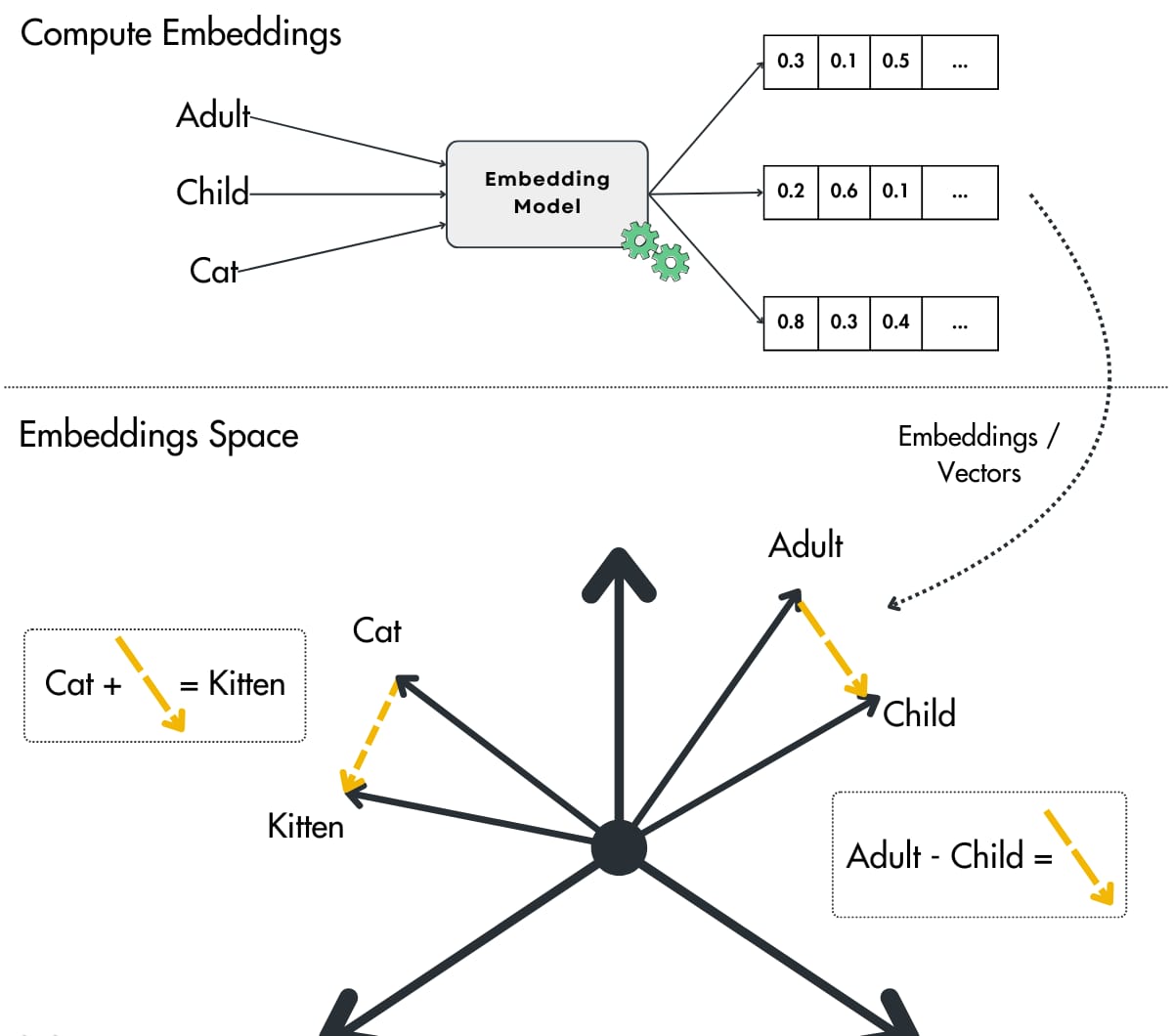
Once generated, each embedding is saved for retrieval. This makes it possible to compare new images or text directly against the stored vectors without recomputing the entire dataset.
embeddings/ ├─ embedding_001_image.pt ├─ embedding_001_text.pt ├─ embedding_002_image.pt └─ embedding_002_text.pt
Applications
Mapping images and text into a unified vector space creates several practical capabilities.
- Searching for images using natural language descriptions.
- Measuring similarity between visual and textual concepts.
- Building recommendation models that combine both image and text features.
- Providing foundations for multimodal AI research and experimentation.